
Сверточные нейронные сети являются мощным инструментом для извлечения характерных признаков из сложных данных. Это задачи распознавания образов в звуковых сигналах или изображениях. В статье обсуждаются преимущества СНС по сравнению с методом классического линейного программирования.
Что такое сверточные нейронные сети? Нейронные сети – это системы или структуры нейронов, которые позволяют ИИ лучше распознавать данные, что дает возможность ИИ решать сложные задачи. Основными областями применения СНС являются задачи распознавания образов и классификации объектов, содержащихся во входных данных. СНС — это искусственная нейронная сеть, используемая в глубоком обучении (deep learning). Такие сети состоят из входного слоя, нескольких сверточных слоев и выходного слоя.
Сверточные слои являются наиболее важными компонентами ИИ, поскольку они используют уникальный набор фильтров, которые позволяют сети извлекать признаки из входных данных. Данные могут поступать во многих формах, таких как изображения объектов, аудиоданные и данные в виде текста.
Процесс извлечения признаков позволяет сетям идентифицировать закономерности в полученных данных. Извлекая зависимости из данных, СНС позволяют инженерам создавать более эффективные и надежные приложения. Чтобы лучше понять работу и преимущества СНС, кратко рассмотрим классический метод линейного программирования, который используется для решения подобных задач.
Выполнение линейной программы в классической системе управления. В системах управления задача, как правило, состоит из считывания данных с одного или нескольких датчиков, последующей их обработки и реакции на полученные данные в виде формирования управляющего воздействия в соответствии с наперед заданными алгоритмами. Например, регулятор температуры измеряет температуру каждую секунду с помощью микроконтроллера, который считывает данные с датчика температуры. Значения, полученные от датчика, служат входными данными для системы управления с обратной связью и сравниваются с заданной температурой в контуре. Это пример линейного управления с помощью микроконтроллера. Такой подход обеспечивает управление на основе набора предварительно запрограммированных, т.е. заранее известных алгоритмов. В отличие от этого детерминированного подхода системы с использованием ИИ, как правило, основаны на применении вероятностного подхода.
Сложные образы и обработка сигналов. Известно множество приложений, работающих с входными данными, которые сначала должны быть интерпретированы системой распознавания образов.
Распознавание образов может применяться к различным структурам данных. В приведенных примерах мы ограничимся одномерными и двумерными структурами данных. К таким данным относятся звуковые сигналы, электрокардиограммы (ЭКГ), фотоплетизмограммы (ФПГ), вибрации для одномерных данных и изображений или тепловые изображения, также многие другие.
При распознавании образов для таких данных разработка приложения в классическом коде микроконтроллера весьма затруднительна. Примером может служить распознавание объекта (например, кота) на изображении. В этом случае не имеет значения, взято ли анализируемое изображение из более ранней записи или только что считано сенсорами видеокамеры. Программное обеспечение для анализа выполняет поиск на основе правил, которые можно отнести к признакам семейства кошачьих: заостренные уши, треугольный нос, наличие усов.
Если эти особенности можно распознать на изображении, программа сообщает о наличии кота на данном изображении. При этом возникают дополнительные вопросы: что будет делать система распознавания образов, если кота показывают только со спины? Что было бы, если бы у кота не было усов или он потерял лапу в результате несчастного случая? Несмотря на маловероятность этих исключений, алгоритмам распознавания образов пришлось бы проверять во много раз большее количество дополнительных данных, покрывающих все возможные аномалии. Даже в этом, казалось бы, простом примере количество алгоритмов, заложенных в программное обеспечение, будет стремительно возрастать.
Как машинное обучение заменяет классические методы и алгоритмы. Идея применения ИИ состоит в том, чтобы имитировать обычное (человеческое) обучение в рамках поставленной задачи.
Вместо того, чтобы заранее предусматривать большое количество правил (алгоритмов), моделируется универсальная система распознавания образов. Ключевое различие между двумя подходами заключается в том, что ИИ, в отличие от набора алгоритмов, не дает четкого результата. Вместо сообщения в виде «Я узнал кота на изображении», результатом машинного обучения является некоторая вероятность, когда результат формулируется в виде “С вероятностью 97,5% на изображении кот. Это также может быть леопард (2,1%) или тигр (0,4%)”.
В связи с этим разработчик такого приложения должен принять самостоятельное решение в конце процесса распознавания образов. Для этого используется порог принятия единственного решения. Еще одно отличие состоит в том, что система распознавания образов не оснащена заранее фиксированными правилами (алгоритмами). Вместо этого она обучается. В этом процессе обучения нейронной сети показывается большое количество изображений котов. В конце концов, эта сеть с некоторой вероятностью способна самостоятельно распознать, есть ли на изображении кот или его нет. Важным моментом такого решения является то, что процесс распознавания не ограничивается известными заранее тренировочными изображениями. Для построения реальной системы распознавания нейронную сеть необходимо встроить в микроконтроллер или микропроцессор.
Что из себя представляет система для распознавания образов? Сеть нейронов в ИИ напоминает биологический аналог мозга человека.
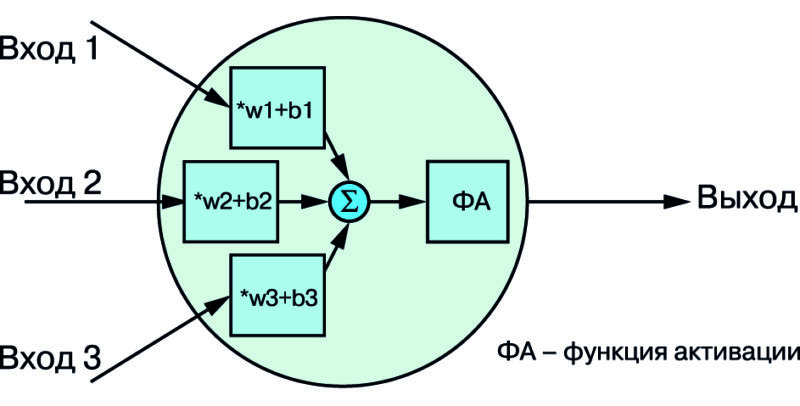
Рис. 1. Нейрон с тремя входами и одним выходом
Нейрон имеет несколько входов и один выход. По сути, такой нейрон представляет собой не что иное, как линейное преобразование входных данных — умножение входных данных на числа (веса, w) и добавление константы (смещение, b) — за которыми следует фиксированная нелинейная функция, также известная как функция активации. Функция активации, как единственный нелинейный компонент сети, служит для определения диапазона значений, в котором работает искусственный нейрон. Функция нейрона может быть описана математически как
Out = f(w•x + b),
где f – функция активации, w – вес, x – входные данные и b – смещение.
Данные могут быть представлены в скалярном или векторном виде, а также в матричной форме. На рис. 1 показан нейрон с тремя входами и функцией активации (ФА). Нейроны в сети всегда располагаются слоями.
Как уже упоминалось, СНС используются для распознавания образов и классификации объектов, содержащихся во входных данных. Сеть включает входной слой, несколько скрытых слоев и один выходной слой. На рис. 2 показан фрагмент сети с тремя входами, одним скрытым слоем с пятью нейронами и одним выходным слоем с четырьмя выходами. Все выходы нейронов подключены ко всем входам следующего слоя. Сеть на рис. 2 не предназначена для решения сложных задач и используется в качестве примера. Даже в этой несложной сети в уравнении для ее описания содержится 32 смещения и 32 веса.
Для обучения нейронных сетей используются специальные наборы данных. Набор CIFAR-10 – один из таких наборов данных (изображений), обычно используемый для обучения нейронных сетей типа CIFAR для распознавания образов.

Рис. 2. Простая нейронная сеть
Набор состоит из 60 000 цветных изображений 32Ч32, разбитых на 10 классов, которые собраны из различных источников, таких как веб-страницы, группы новостей, частные коллекции изображений и т.п. Каждый класс содержит 6000 изображений, поровну разделенных на наборы для обучения, тестирования и проверки, что делает его идеальным для тестирования новых систем компьютерного зрения и других моделей машинного обучения. Модель обучения СНС на наборе CIFAR-10 приведена на рис. 3.
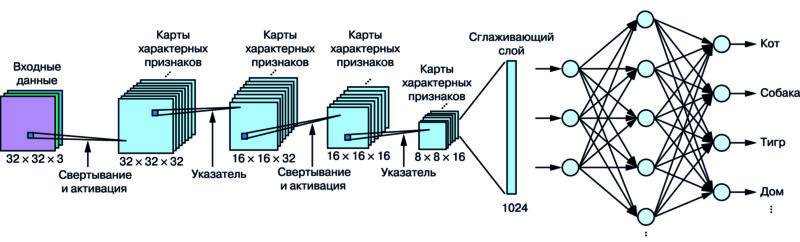
Рис. 3. Модель обучения нейронной сети на наборе CIFAR-10
Основное отличие сверточных нейронных сетей от других типов сетей заключается в обработке данных. С помощью фильтрации входные данные последовательно проверяются на предмет их свойств. По мере увеличения количества сверточных слоев, соединенных последовательно, увеличивается уровень детализации, которую можно распознать. Процесс начинается с простых свойств объекта, таких как ребра или точки, после первой свертки и переходит к детальным структурам, таким как углы, круги, прямоугольники и т. д., после второй свертки. После третьей свертки признаки представляют собой сложные шаблоны (фрагменты изображения), которые напоминают части объектов на изображениях и обычно являются уникальными для данного класса распознаваемых объектов. В исходном примере это усы или уши кота. Визуализация карт признаков, которую можно увидеть на рис. 4, не является необходимой для самого приложения, но помогает понять процесс свертки.

Рис 4. Карты характерных признаков
Даже у достаточно простой сети типа CIFAR содержатся сотни нейронов в каждом слое и множество последовательно соединенных слоев. Количество необходимых весов и смещений растет с увеличением сложности и размера сети. В примере CIFAR-10 (рис. 3) уже имеется 200 000 параметров, которым соответствует определенный набор характерных признаков в процессе обучения. Карты объектов могут быть дополнительно обработаны путем объединения слоев для уменьшения количества параметров обучения.
Как уже было отмечено, после каждой свертки в СНС часто происходит объединение, называемое в литературе подвыборкой. Это служит для уменьшения размерности данных. Если посмотреть на наборы (карты) объектов на рис. 4, то можно заметить, что ряд фрагментов содержит малозначимую информацию или вообще ее не содержат. Это связано с тем, что объекты составляют не все изображение, а лишь небольшую его часть. Остальная часть изображения не используется в конкретной карте признаков и, следовательно, не имеет отношения к классификации.
В слое группы указывается как тип группы (максимальный или средний), так и размер матрицы окна. Матрица окна поэтапно перемещается по входным данным в процессе объединения. Например, при максимальном объединении берется наибольшее значение данных в окне. Все остальные значения отбрасываются.
Таким образом, количество данных постоянно уменьшается, и, в конце концов, они формируют вместе со свертками уникальные свойства соответствующего класса объектов. Результатом этих групповых сверток и объединений является большое количество двумерных матриц. Чтобы достичь фактической цели классификации, необходимо преобразовать двумерные данные в один одномерный вектор.
Преобразование выполняется в так называемом выравнивающем или сглаживающем слое, за которым следуют один или два полносвязных слоя. Нейроны последних двух типов слоев аналогичны структуре, приведенной на рис. 2.
Последний слой этой нейронной сети имеет ровно столько выходов, сколько классов нужно различать. Кроме того, в последнем слое данные также нормализуются для получения распределения вероятностей (97,5 % коты, 2,1 % леопарды, 0,4 % тигры и т. д.).На этом пример моделирования рассмотренной нейронной сети завершен. В последующих статьях на эту тему будет рассмотрена аппаратная реализация сверточной нейронной сети с применением микроконтроллера MAX78000 и аппаратным ускорителем СНС, разработанным компанией Analog Devices.
ВЫВОДЫ
В вычислительных задачах большой сложности широко применяются элементы искусственного интеллекта, основным инструментом которого являются обучаемые нейронные сети. Особенности построения и обучения таких систем кратко изложены в настоящей публикации. В дальнейших работах автора будет рассмотрена аппаратная реализация таких сетей, выполненная на компонентах компании Analog Devices.